强化学习动手实践:初探 DeepSeek R1 顿悟现象
在人工智能训练过程中,模型能力的跃迁往往并非线性提升,而是伴随着潜移默化的积累与突现的顿悟。本文以小模型为例,尝试通过强化学习探索 DeepSeek R1 中“顿悟现象”的再现与分析,揭示智能系统从量变到质变的过程。
一、实践目的
我们实践的目标包括:
- 探索语言模型在强化学习中表现出来的“顿悟”(Aha Moment)现象,即模型能力出现显著提升的瞬间。
- 理解模型训练过程中每个代码模块的作用,并实际动手完成一次训练。
本教程基于 Philipp Schmid 在 GitHub 上公开的 Mini-R1: Reproduce Deepseek R1 „aha moment“ a RL tutorial 项目修改而来。代码和实验结果可以从 Github 或者 Gitee 下载。
二、强化学习任务介绍
强化学习的问题设定:
我们使用的数据集为 Jiayi-Pan/Countdown-Tasks-3to4,包含大量以数字运算为核心的数学问题。具体来说,每个题目都会提供:
- 一组数字(例如
80, 93, 62) - 一个目标数字(例如
49)
任务是:
使用给定的数字,每个数字且只能使用一次,通过基本的数学运算(加、减、乘、除)组合成一个算式,得到题目给出的目标数字。
举例说明:
给定数字:80, 93, 62,目标:49
生成的 completion 样例如下:
<think>
We need to use the numbers 80, 93, and 62 exactly once with basic arithmetic operations to get 49. Let's try different combinations:
:
- 93 - 80 - 62 = -49(not 49)
- 80 + 62 - 93 = 49(this works)
</think>
<answer>80 + 62 - 93</answer>
模型需要先在 <think> 标签内展示思考推导过程,然后在 <answer> 标签内给出最终正确的算式。
三、实践框架概览
实践过程可分为以下几个主要阶段:
- 环境配置
- 数据准备与格式化(Prompt构建)
- 定义奖励函数用于评估生成结果
- 模型加载并运行 GRPO 训练
- 训练结果分析与顿悟现象识别
四、具体实践步骤
步骤 1:环境配置
本实践是在 Spader.AI 上的 8 卡 A100 上完成的。按照 Github 或者 Gitee 上的安装指南准备环境。
以下代码片段均来自 scripts/run_r1_grpo.py。
步骤2:数据准备与 Prompt 格式化
从 Hugging Face 数据集Jiayi-Pan/Countdown-Tasks-3to4中抽取数据后,使用如下代码格式化成 Prompt:
# 从 Hugging Face Hub 下载数据集
dataset = load_dataset(script_args.dataset_id_or_path, split=script_args.dataset_splits)
# 从中随机挑选 5 万个样本
dataset = dataset.shuffle(seed=42).select(range(50000))
#####################
# 准备并且格式化数据
#####################
# 转换成 DeepSeek R1 prompt 格式, 即带有 <think> 标签开头的 prompt
def generate_r1_prompt(numbers, target):
r1_prefix = [{
"role": "system",
"content": "You are a helpful assistant. You first thinks about the reasoning process in the mind and then provides the user with the answer."
},
{
"role": "user",
"content": f"Using the numbers {numbers}, create an equation that equals {target}. You can use basic arithmetic operations (+, -, *, /) one or multiple times but each number can only be used once. Show your work in <think> </think> tags. And return the final equation in <answer> </answer> tags, for example <answer> (1 + 2) / 3 </answer>. Think step by step inside <think> tags."
},
{
"role": "assistant",
"content": "Let me solve this step by step.\n<think>"
}]
return {"prompt": tokenizer.apply_chat_template(r1_prefix, tokenize=False, continue_final_message=True), "target": target, "nums": numbers}
# 把待训练的数据转换成 DeepSeek R1 格式的 prompt
dataset = dataset.map(lambda x: generate_r1_prompt(x["nums"], x["target"]))
# 切分 10% 的数据作为测试集
train_test_split = dataset.train_test_split(test_size=0.1)
train_dataset = train_test_split["train"]
test_dataset = train_test_split["test"]
格式化后的 Prompt 具体内容包含:
- 清晰的系统指令,要求模型先思考后作答。
- 用户问题明确要求模型用给定数字构造等于目标的算式,并明确要求在
<think>标签内展示推导过程、<answer>标签内给出最终算式。 - Assistant 回复的开头固定为
Let me solve this step by step.<think>以引导模型的推理流程。
步骤3:奖励函数定义(评估模型生成结果)
format_reward_func用于检查输出是否满足<think>和<answer>格式要求。equation_reward_func用于检查算式的数学正确性、数字是否用尽且仅使用一次,以及是否等于目标值。
奖励值为 1 表示成功,0 表示失败。奖励函数帮助模型学习生成满足要求的高质量答案。
步骤4:GRPO 模型训练
#########################
# 初始化 GRPO trainer
#########################
trainer = GRPOTrainer(
model=model_args.model_name_or_path,
reward_funcs=[format_reward_func, equation_reward_func],
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
peft_config=get_peft_config(model_args), # 此实践没有用到 Lora
)
###############
# Training loop
###############
train_result = trainer.train(resume_from_checkpoint=last_checkpoint)
步骤 5:启动训练
本实践采用 DeepSpeed Zero Stage 3 高效分布式训练框架,使用 Qwen2.5-3B-Instruct 模型作为基础模型。配置信息通过如下命令装载并启动训练。因为采用的是 8 卡 A100 训练模型,利用了前 7 个 GPU 进行训练,最后一个 GPU 给 vLLM 对每个 prompt 生成答案使用,因此 num_processes 设置为 7。配置文件里的 vllm 配置改为最后一个 GPU,即 vllm_device: "cuda:7"。
accelerate launch --num_processes 7 \
--config_file configs/accelerate_configs/deepspeed_zero3.yaml \
scripts/run_r1_grpo.py \
--config receipes/grpo-qwen-2.5-3b-deepseek-r1-countdown.yaml
训练启动后,观察到每个 step 耗时 3 分到 3 分半钟。同时通过日志(TensorBoard)跟踪:
- 奖励(reward)指标变化,查看是否存在明显跃升。
- 观察生成的
success_completion_samples.txt样本文件,可直观看出模型生成的算式何时明显改善,以便定位顿悟时刻。
五、结果分析
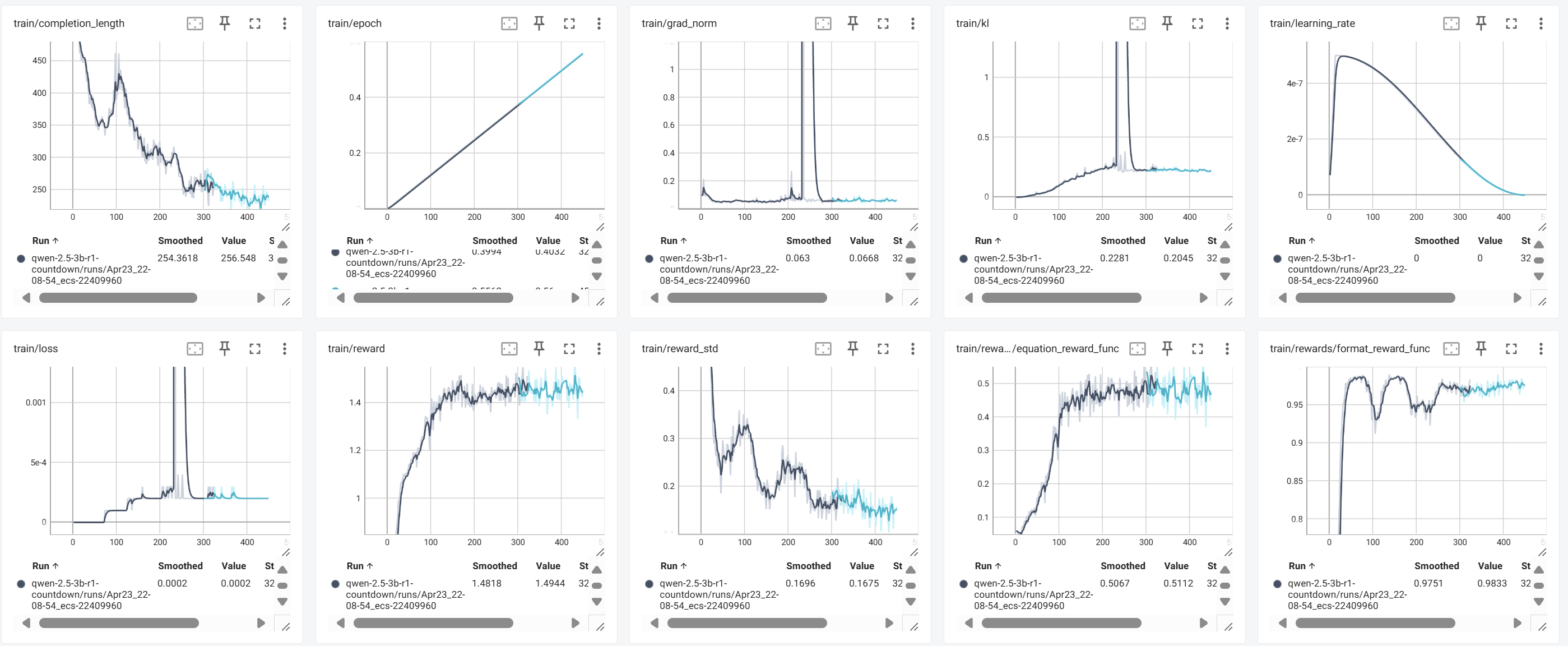
上图是训练 450 steps 的结果,从训练过程看,模型整体表现良好。我们从训练有效性、奖励函数效果、稳定性分析、生成变化趋势和顿悟时刻探测五个方面进行系统分析。
1. 总体趋势:训练稳定,效果明显
| 指标 | 表现 | 分析结论 |
|---|---|---|
train/reward | 平稳上升至 1.4+ | 模型持续学习,奖励稳定增长 |
equation_reward_func | 稳定在 0.5 左右 | 有约一半样本正确解答 |
format_reward_func | 达到 0.98+ | 几乎所有输出符合格式要求 |
train/loss | 基本收敛,偶有抖动 | 局部不稳定,但整体可控 |
train/kl & train/grad_norm | 出现短暂峰值后恢复 | 正常探索现象,无长期发散 |
train/completion_length | 明显下降 | 输出更简洁,推理更高效 |
整体趋势表明,模型在强化训练下取得了有效进展,训练过程健康稳定。
2. 奖励函数表现与学习过程
train/reward 与 train/reward_std
- 奖励从 0.9 快速上升至 1.4+,保持平稳增长。
- 奖励标准差
reward_std从 0.4+ 降至 0.1-0.15,输出趋于一致,训练收敛明显。
equation_reward_func
- 由 0 上升至 0.5 左右,表明模型部分掌握了解题策略。
- 后期提升变缓,提示出现了策略学习瓶颈。
format_reward_func
- 初期即快速达到 0.95+,最终稳定在 0.98-0.99。
<think>和<answer>的结构化输出学习非常成功。
3. 稳定性分析:loss、梯度与KL变化
train/loss & train/grad_norm
- Step 200-250 期间出现短暂尖峰,随后迅速回落,恢复正常。
- 说明局部探索剧烈,但整体数值稳定性良好。
train/kl
- 随训练缓慢上升,表明模型逐步脱离初始策略,策略更新正常。
- KL 的短期飙升与 loss/grad_norm 同步,属于合理范围内的策略探索。同时期 reward / accuracy / format_reward 基本不变或缓慢上升,很可能是在这个时刻模型学会了一个新的表达方式或者新的能力。completion length 这个时间点也在明显的下降,说明模型应该是学会了简单明了地回答问题。
总体来看,训练过程中出现的波动是强化学习中典型现象,没有长期发散,符合预期。
4. 生成长度变化与行为演变
train/completion_length
- 生成长度从 450+ token 下降至 230 左右。
- 反映出模型推理过程更加简洁高效,减少冗余。
生成演变过程
| 阶段 | 特征 | 说明 |
|---|---|---|
| 初期 (step 0-30) | 胡言乱语、超时终止 | 格式尚未掌握,推理混乱 |
| 成长期 (step 30-80) | 逐步掌握格式 | reward 与格式准确率同步上升 |
| 提升期 (step 80-150) | 尝试多种路径,投机取巧迹象 | 尝试优化 reward,但答案质量不高 |
| 收敛期 (step 150-250) | 简洁推理,直接解题 | 真正掌握了任务结构与推理方法 |
小结:
Completion Length 的下降是模型真正理解任务、推理能力提升的重要标志,而非简单的格式符合或投机取巧。
5. 顿悟时刻分析:有没有“aha moment”?
顿悟(Aha Moment)通常是指模型在短时间内突然掌握任务技巧,奖励曲线陡然上升的现象。我们结合训练曲线与 success completion 样本分析:
- 没有典型的顿悟跳变。
- 奖励、正确率均呈持续平滑上升,没有突然的跃升。
- 成功样本中的
<think>表达从冗长尝试转向简洁推理,大约发生在 step 250 左右,但变化是渐进式的,而非突发式的。
success completion 样本变化示例
早期(step ≈ 0-150)
在前 30 步,回答要么格式不正确,要么超出 prompt 长度限制被提前终止(类似于“考试超时了”),要么就是胡言乱语,瞎给一个答案。然后,30 步以后,在激励情况下开始思考正确的答案,但依然碎�碎叨叨,装作很懂似的,模型回答的风格类似于这样:
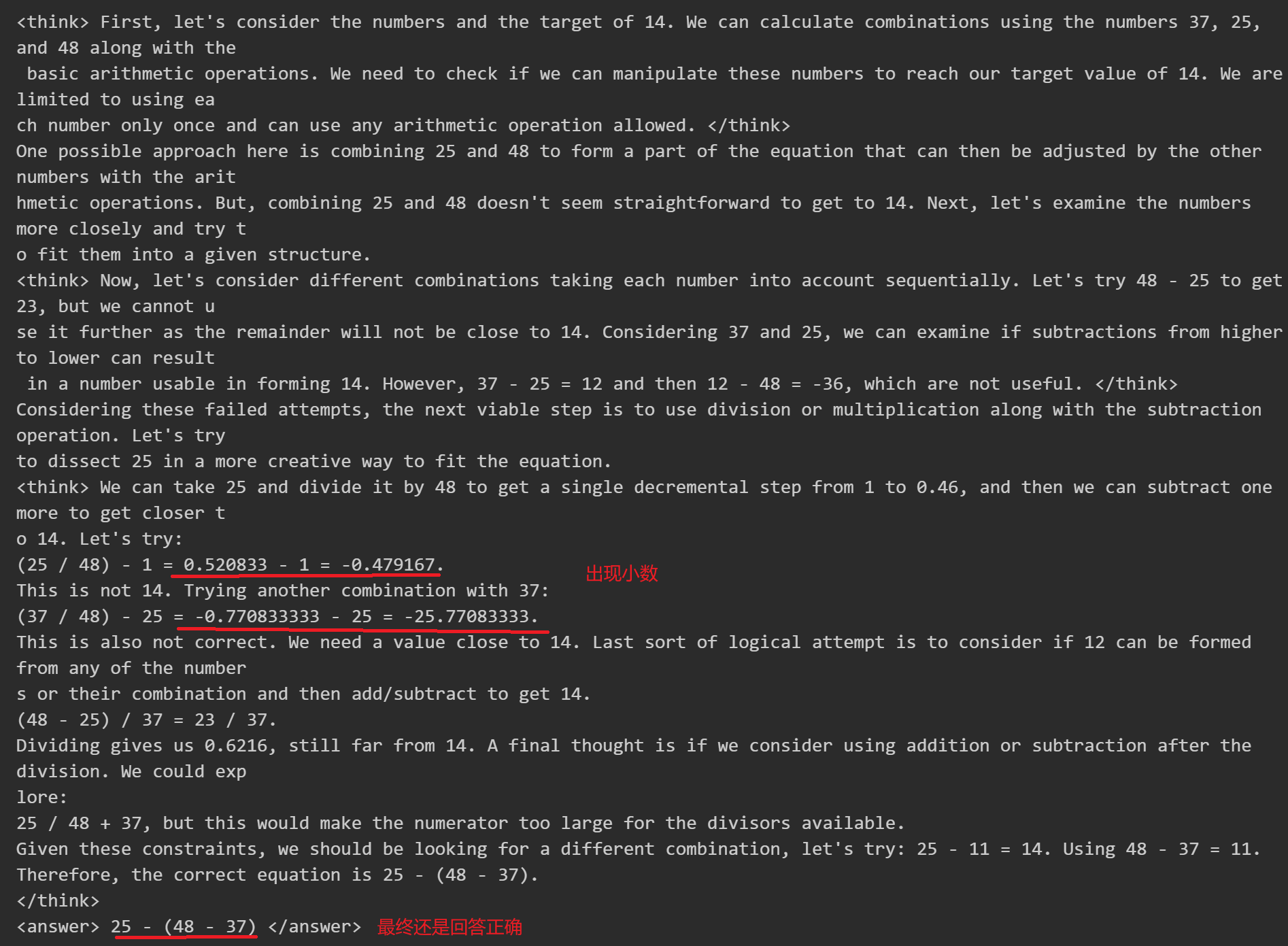
- 推理链冗长,反复试探。
中期(step ≈ 150-250)
中期回答风格类似于以下:
- 有明确目标,但推理过程中仍有多路径尝试。 在 RL 类训练中,模型可能会“投机取巧”通过:
- 拼命堆叠
<think>内容、加入花哨词汇; - 拖长输出,碰运气地命中答案;
- 这些会让 reward 增高,但对用户没太大意义。
- 拼命堆叠
后期(step ≈ 250+)
后期开始真正掌握技巧,回答风格如下:

- 推理简洁直接,无冗余话术,模型变得聪明和自信了。
- 技术原理上是由于策略的简化:从复杂策略突然收敛到高效策略(如 RL 策略网络丢弃冗余动作分支)
结论:出现了渐进式的能力提升,虽然没有发现突发性性能跳跃��的“顿悟点”,但是从反复试错到突然找到简洁解决方案的思维跃迁,正是人类认知中典型的“顿悟现象”(Aha Moment),也是大模型或 AI 系统中可能出现的类似能力的体现。这种过程体现了量变到质变的认知飞跃。
6. 后续训练与优化建议
本次实验正确率一直停留在 50% 左右,貌似到了一个瓶颈,即使延长训练时间到 750 steps,也没有出现顿悟时刻,而且几个关键指标很平稳,reward 依然保持在 1.4 左右,说明现有手段大概率到了一个瓶颈。分析原因有几个:
- 模型太小,DeepSeek R1 论文 提到过强化学习对小模型效果不佳。
- 数据量太少或者单一,可以尝试少量的合成难样本(curriculum learning)。
- 激励机制太简单,当前奖励函数简单将格式和正确性相加,可以引入更精细的奖励设计,
训练中可以考虑加入 reward shaping(例如惩罚重复运算、惩罚长度)。对部分解对给予一定奖励
(如果模型思路接近正确但计算错误,可以给部分分以引导逐步纠正),或者引入基于步骤合理性的奖励
(奖励
<think>中逻辑正确的推理步骤)。这样可以提供更平滑的反馈,帮助模型逐步接近完美解答, 而不是仅靠最终对/错的二元奖励。
总结
本次基于 GRPO 的 DeepSeek R1 风格训练实验表明,小模型在合理设置下可以通过强化学习显著提升推理能力与输出质量。虽然未出现明显的顿悟时刻,但整体训练趋势积极健康,为后续更复杂任务的强化学习探索打下了良好基础。