昆仑芯 P800 环境 Qwen3 部署与全参 DPO 训练实践指南
太长不看(阅读时间:约 15 分钟):
- 测试环境:8 卡昆仑芯 P800(驱动 5.0.21.21)+ Ubuntu 22.04 + Docker 镜像
xpu_dev_20251202_172933-with-lf - 性能实测:Qwen3-32B(TP=8)吞吐 1184 tok/s / TTFT 1.8s,Qwen3-VL(TP=4)吞吐 1942 tok/s,Qwen3-8B(TP=1)吞吐 1667 tok/s
- 技术方案:vLLM-Kunlun 提供 OpenAI 兼容推理服务 + LLaMA-Factory 全参数 DPO 训练(81.9B 参数,8 分钟/轮)
- 实用价值:提供可直接运行的启动脚本、张量并行配置、显存优化参数、完整 Benchmark 命令与训练配置
本文档将详细介绍在 昆仑芯 P800 XPU 物理机环境下部署 Qwen3-8B / Qwen3-32B / Qwen3-VL-8B-Instruct 模型,并基于 LLaMA-Factory 完成全参数 DPO 训练的完整流程。内容覆盖环境检查、容器准备、模型推理、性能测试和训练输出解析,适合作为在国产算力平台上落地 Qwen3 的实战手册。
整体架构:物理机安装昆仑芯驱动与运行时,通过官方 vLLM-Kunlun 适配的推理镜像启动 Docker 容器,在容器内使用 vLLM 提供 OpenAI 兼容 HTTP 服务,辅以 LLaMA-Factory 完成 Qwen3-8B 的全参数 DPO 训练。
适用读者:已经具备基础 Linux 与 Docker 使用经验,希望在昆仑芯 P800 上快速跑通 Qwen3 推理与训练的研发 / 运维工程师。
1. 昆仑芯 P800 与测试环境概览
1.1 昆仑芯 P800 简介
昆仑芯(Kunlun XPU)是百度自研的通用 AI 芯片产品线,P800 是面向云端大模型场景的新一代推理 / 训练加速卡,支持 OAM 形态部署,主要特点包括:
- 面向大模型优化:针对 LLM 推理与训练场景进行了算力调度与内存访问优化,适合 Qwen3、DeepSeek 等百亿级以上参数模型的长上下文推理。
- 高带宽互联:支持高带宽片间互联,配合 vLLM 的张量并行(Tensor Parallel),可在多卡场景下保持较高的扩展效率。
- 生态适配完善:官方提供对 PyTorch / vLLM 的硬件插件(如 vLLM-Kunlun),在容器镜像中预置 XPU runtime、编译器与必要算子库,降低环境搭建门槛。
本篇文章不会深入芯片微架构细节,更关注 如何在真实生产环境中稳定跑通 Qwen3。
1.2 物理机环境信息
以下为实际测试环境的硬件与系统信息:
root@h3c:/mnt/nvme# lscpu | grep "Model name"
Model name: Hygon_7470
root@h3c:/mnt/nvme# lscpu | grep Architecture
Architecture: x86_64
root@h3c:/mnt/nvme# free -g
total used free shared buff/cache available
Mem: 1507 24 579 0 903 1475
Swap: 7 0 7
root@h3c:/mnt/nvme# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
loop0 7:0 0 63.9M 1 loop /snap/core20/2318
loop1 7:1 0 87M 1 loop /snap/lxd/29351
loop2 7:2 0 38.8M 1 loop /snap/snapd/21759
sda 8:0 0 447.1G 0 disk
├─sda1 8:1 0 1G 0 part /boot/efi
├─sda2 8:2 0 2G 0 part /boot
└─sda3 8:3 0 444G 0 part
└─ubuntu--vg-ubuntu--lv 253:1 0 444G 0 lvm /
nvme0n1 259:0 0 3.5T 0 disk
└─nvme0n1p1 259:2 0 3.5T 0 part /mnt/nvme
nvme1n1 259:1 0 3.5T 0 disk
└─nvme_vg-docker_lv 253:0 0 3.5T 0 lvm /mnt/nvmelvm
root@h3c:/mnt/nvme# cat /etc/issue
Ubuntu 22.04.5 LTS \n \l
root@h3c:/mnt/nvme# uname -r
5.15.0-119-generic
昆仑芯 P800 设备与驱动版本:
root@h3c:/mnt/nvme# xpu-smi -q | grep -i "Product Name"
Product Name : P800 OAM
Product Name : P800 OAM
Product Name : P800 OAM
Product Name : P800 OAM
Product Name : P800 OAM
Product Name : P800 OAM
Product Name : P800 OAM
Product Name : P800 OAM
root@h3c:/mnt/nvme# xpu-smi -q | grep -i "All Version"
ALL Version : 1.0.2.16.1.49
ALL Version : 1.0.2.16.1.49
ALL Version : 1.0.2.16.1.49
ALL Version : 1.0.2.16.1.49
ALL Version : 1.0.2.16.1.49
ALL Version : 1.0.2.16.1.49
ALL Version : 1.0.2.16.1.49
ALL Version : 1.0.2.16.1.49
root@h3c:/mnt/nvme# xpu-smi -q | grep -i "Driver Version"
Driver Version : 5.0.21.21
1.3 Docker 与镜像概览
Docker 版本信息如下:
root@h3c:/mnt/nvme# docker version
Client: Docker Engine - Community
Version: 29.1.3
API version: 1.52
Go version: go1.25.5
Git commit: f52814d
Built: Fri Dec 12 14:49:37 2025
OS/Arch: linux/amd64
Context: default
Server: Docker Engine - Community
Engine:
Version: 29.1.3
API version: 1.52 (minimum version 1.44)
Go version: go1.25.5
Git commit: fbf3ed2
Built: Fri Dec 12 14:49:37 2025
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: v2.2.1
GitCommit: dea7da592f5d1d2b7755e3a161be07f43fad8f75
runc:
Version: 1.3.4
GitCommit: v1.3.4-0-gd6d73eb8
docker-init:
Version: 0.19.0
GitCommit: de40ad0
本实践环境中与昆仑芯 XPU 适配的大模型推理镜像如下:
root@h3c:/mnt/nvme# docker images
h3c-repack-qwen3_32b-ubuntu22.04:20250725-v1.0 b12133610dc3 66.5GB 33GB U
aiak-inference-llm:vllm_kunlun_20250917_214552 feb894951c53 105GB 52GB
aiak-inference-llm:xpu_dev_20251105_151131-vllm01011-awq 2b09210d3113 114GB 56.3GB
aiak-inference-llm:xpu_dev_20251202_172933 e98a5cf79b1b 132GB 65.7GB U
aiak-inference-llm:xpu_dev_20251202_172933-with-lf 30d22a3c953e 135GB 66.4GB U
aiak-inference-llm:xpu_dev_20251216_162351 f4fa5bb931c5 96.1GB 47.7GB U
其中:
xpu_dev_20251202_172933-with-lf:支持 Qwen3 / Qwen3-VL,内置 LLaMA-Factory,是本文推荐使用的镜像。- 其他镜像用于不同版本 vLLM-Kunlun 或量化方案,可按需选择。
建议:如果只是想快速跑通 Qwen3 推理 + DPO 训练,建议直接使用
xpu_dev_20251202_172933-with-lf。
2. 容器与目录准备
2.1 目录约定
物理机上的目录约��定如下:
/mnt/nvme/runtimes:存放启动脚本与示例模型权重,挂载到容器内的/home/workspace。/workspace:容器内预置的代码目录,包含vllm、vllm-kunlun、LLaMA-Factory等仓库。
后续所有与模型相关的操作,均在容器内部完成。
2.2 启动推理容器
以下脚本用于启动带有 vLLM-Kunlun 与 LLaMA-Factory 的推理容器:
root@h3c:/mnt/nvme/runtimes# cat docker_run_xpu_dev_20251202_172933-with-lf.sh
#!/bin/bash
docker run -itd \
--net=host \
--pid=host \
--cap-add=SYS_PTRACE --security-opt=seccomp=unconfined \
--ulimit=memlock=-1 --ulimit=nofile=120000 --ulimit=stack=67108864 \
--shm-size=128G \
--privileged \
-v /usr/local/bin/:/usr/local/bin/ \
--name=xpu_dev_20251202_172933-with-lf \
-v /mnt/nvme/runtimes:/home/workspace \
-w /workspace \
-v /lib/x86_64-linux-gnu/libxpunvidia-ml.so.1:/lib/x86_64-linux-gnu/libxpunvidia-ml.so.1 \
aiak-inference-llm:xpu_dev_20251202_172933-with-lf bash
docker exec -it xpu_dev_20251202_172933-with-lf /bin/bash
--net=host:使用 Host 网络,方便在物理机上直接访问容器内的 8999 端口。--shm-size=128G:为 vLLM 提供足够的共享内存,避免大批量推理时报shm相关错误。-v /mnt/nvme/runtimes:/home/workspace:挂载脚本与本地模型目录,是后续操作的核心路径。
不建议 随意修改上述脚本中的
ulimit、shm-size等参数,除非清楚带来的影响。
容器启动并进入后,可以看到如下目录结构:
(python310_torch25_cuda) root@h3c:/workspace# ls
LLaMA-Factory transformers vllm vllm-kunlun
(python310_torch25_cuda) root@h3c:/workspace# cd /home/workspace/
(python310_torch25_cuda) root@h3c:/home/workspace# ls
docker_run_xpu_dev_20251202_172933-with-lf.sh Qwen3-32B Qwen3-8B qwen3_full_dpo.yaml Qwen3-VL-8B-Instruct run_qwen3_32b.sh run_qwen3_8b.sh run_qwen3_vl_8b.sh
小结:后续的推理与训练命令,统一在容器内部的
/home/workspace与/workspace/LLaMA-Factory下执行。
3. Qwen3 推理服务部署(vLLM-Kunlun)
本节将分别介绍基于 vLLM-Kunlun 在昆仑芯 P800 上启动 Qwen3-8B、Qwen3-32B、Qwen3-VL-8B-Instruct 的推理服务。
3.1 Qwen3-8B 启动脚本
查看示例脚本:
(python310_torch25_cuda) root@h3c:/home/workspace# cat run_qwen3_8b.sh
unset XPU_DUMMY_EVENT
export XPU_VISIBLE_DEVICES=0
export XPU_USE_MOE_SORTED_THRES=1
export XFT_USE_FAST_SWIGLU=1
export XMLIR_CUDNN_ENABLED=1
export XPU_USE_DEFAULT_CTX=1
export XMLIR_FORCE_USE_XPU_GRAPH=1
export XPU_USE_FAST_SWIGLU=1
export XMLIR_ENABLE_MOCK_TORCH_COMPILE=false
export USE_ORI_ROPE=1
VLLM_USE_V1=1 python -m vllm.entrypoints.openai.api_server \
--host 0.0.0.0 \
--port 8999 \
--model /home/workspace/Qwen3-8B/ \
--gpu-memory-utilization 0.95 \
--trust-remote-code \
--max-model-len 32768 \
--tensor-parallel-size 1 \
--dtype float16 \
--max_num_seqs 128 \
--max_num_batched_tokens 32768 \
--block-size 128 \
--no-enable-prefix-caching \
--no-enable-chunked-prefill \
--distributed-executor-backend mp \
--compilation-config '{"splitting_ops": ["vllm.unified_attention",
"vllm.unified_attention_with_output",
"vllm.unified_attention_with_output_kunlun",
"vllm.mamba_mixer2",
"vllm.mamba_mixer",
"vllm.short_conv",
"vllm.linear_attention",
"vllm.plamo2_mamba_mixer",
"vllm.gdn_attention",
"vllm.sparse_attn_indexer"]}'
XPU_VISIBLE_DEVICES=0:单卡推理,仅使用一片 P800。--tensor-parallel-size 1:关闭张量并行,适合中小规模模型与简单评测。--gpu-memory-utilization 0.95:允许 vLLM 使用约 95% 的显存,避免显存碎片导致 OOM。
3.2 Qwen3-32B 启动脚本
Qwen3-32B 需要 8 卡张量并行:
(python310_torch25_cuda) root@h3c:/home/workspace# cat run_qwen3_32b.sh
unset XPU_DUMMY_EVENT
export XPU_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
export XPU_USE_MOE_SORTED_THRES=1
export XFT_USE_FAST_SWIGLU=1
export XMLIR_CUDNN_ENABLED=1
export XPU_USE_DEFAULT_CTX=1
export XMLIR_FORCE_USE_XPU_GRAPH=1
export XPU_USE_FAST_SWIGLU=1
export XMLIR_ENABLE_MOCK_TORCH_COMPILE=false
export USE_ORI_ROPE=1
VLLM_USE_V1=1 python -m vllm.entrypoints.openai.api_server \
--host 0.0.0.0 \
--port 8999 \
--model /home/workspace/Qwen3-32B/ \
--gpu-memory-utilization 0.95 \
--trust-remote-code \
--max-model-len 32768 \
--tensor-parallel-size 8 \
--dtype float16 \
--max_num_seqs 128 \
--max_num_batched_tokens 32768 \
--block-size 128 \
--no-enable-prefix-caching \
--no-enable-chunked-prefill \
--distributed-executor-backend mp \
--compilation-config '{"splitting_ops": ["vllm.unified_attention",
"vllm.unified_attention_with_output",
"vllm.unified_attention_with_output_kunlun",
"vllm.mamba_mixer2",
"vllm.mamba_mixer",
"vllm.short_conv",
"vllm.linear_attention",
"vllm.plamo2_mamba_mixer",
"vllm.gdn_attention",
"vllm.sparse_attn_indexer"]}'
XPU_VISIBLE_DEVICES=0,1,2,3,4,5,6,7与--tensor-parallel-size 8配合,实现 8 卡张量并行。- 其余参数与 Qwen3-8B 类似,可以根据业务需要微调。
3.3 Qwen3-VL-8B-Instruct 启动脚本
视觉语言模型对算子与带宽要求更高,推荐使用 4 卡并行:
(python310_torch25_cuda) root@h3c:/home/workspace# cat run_qwen3_vl_8b.sh
unset XPU_DUMMY_EVENT
export XPU_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
export XFT_USE_FAST_SWIGLU=1
export XPU_USE_FAST_SWIGLU=1
export XMLIR_CUDNN_ENABLED=1
export USE_FAST_BF16_FC=true
export XPU_USE_DEFAULT_CTX=1
export XMLIR_FORCE_USE_XPU_GRAPH=1
export XPU_USE_MOE_SORTED_THRES=128
export VLLM_HOST_IP=$(hostname -i)
export XMLIR_ENABLE_MOCK_TORCH_COMPILE=false
export USE_ORI_ROPE=1
export VLLM_USE_V1=1
python -m vllm.entrypoints.openai.api_server \
--host 0.0.0.0 \
--port 8999 \
--model /home/workspace/Qwen3-VL-8B-Instruct/ \
--gpu-memory-utilization 0.9 \
--trust-remote-code \
--max-model-len 32768 \
--tensor-parallel-size 4 \
--dtype float16 \
--max_num_seqs 128 \
--max_num_batched_tokens 32768 \
--block-size 128 \
--no-enable-prefix-caching \
--no-enable-chunked-prefill \
--distributed-executor-backend mp \
--compilation-config '{"splitting_ops": ["vllm.unified_attention",
"vllm.unified_attention_with_output",
"vllm.unified_attention_with_output_kunlun",
"vllm.mamba_mixer2",
"vllm.mamba_mixer",
"vllm.short_conv",
"vllm.linear_attention",
"vllm.plamo2_mamba_mixer",
"vllm.gdn_attention",
"vllm.sparse_attn_indexer"]}'
其中:
USE_FAST_BF16_FC/XFT_USE_FAST_SWIGLU等变量打开了针对 P800 的算子级优化。VLLM_HOST_IP=$(hostname -i)方便在多进程 / 多机部署时进行网络标识。
3.4 启动模型与日志观察
以 Qwen3-VL-8B-Instruct 为例,在容器内执行:
(python310_torch25_cuda) root@h3c:/home/workspace# bash run_qwen3_vl_8b.sh
稍作等待(首次启动需要进行图捕获与 KV Cache 预热),日志中会出现类似输出:
(Worker_TP1 pid=258866) INFO 01-06 18:39:32 [gpu_model_runner.py:3480] Graph capturing finished in 14 secs, took 0.23 GiB
(Worker_TP2 pid=258867) INFO 01-06 18:39:32 [gpu_model_runner.py:3480] Graph capturing finished in 14 secs, took 0.23 GiB
(Worker_TP3 pid=258868) INFO 01-06 18:39:32 [gpu_model_runner.py:3480] Graph capturing finished in 14 secs, took 0.23 GiB
(Worker_TP0 pid=258865) INFO 01-06 18:39:32 [gpu_model_runner.py:3480] Graph capturing finished in 14 secs, took 0.23 GiB
(EngineCore_DP0 pid=258656) INFO 01-06 18:39:32 [core.py:210] init engine (profile, create kv cache, warmup model) took 32.18 seconds
(APIServer pid=258503) INFO 01-06 18:39:36 [loggers.py:147] Engine 000: vllm cache_config_info with initialization after num_gpu_blocks is: 17250
(APIServer pid=258503) INFO 01-06 18:39:36 [api_server.py:1634] Supported_tasks: ['generate']
...
(APIServer pid=258503) INFO 01-06 18:39:36 [api_server.py:1912] Starting vLLM API server 0 on http://0.0.0.0:8999
...
(APIServer pid=258503) INFO: Application startup complete.
看到 Starting vLLM API server ... 与 Application startup complete. 即表明服务启动成功。
运行时显卡占用示例(vLLM 推理服务):
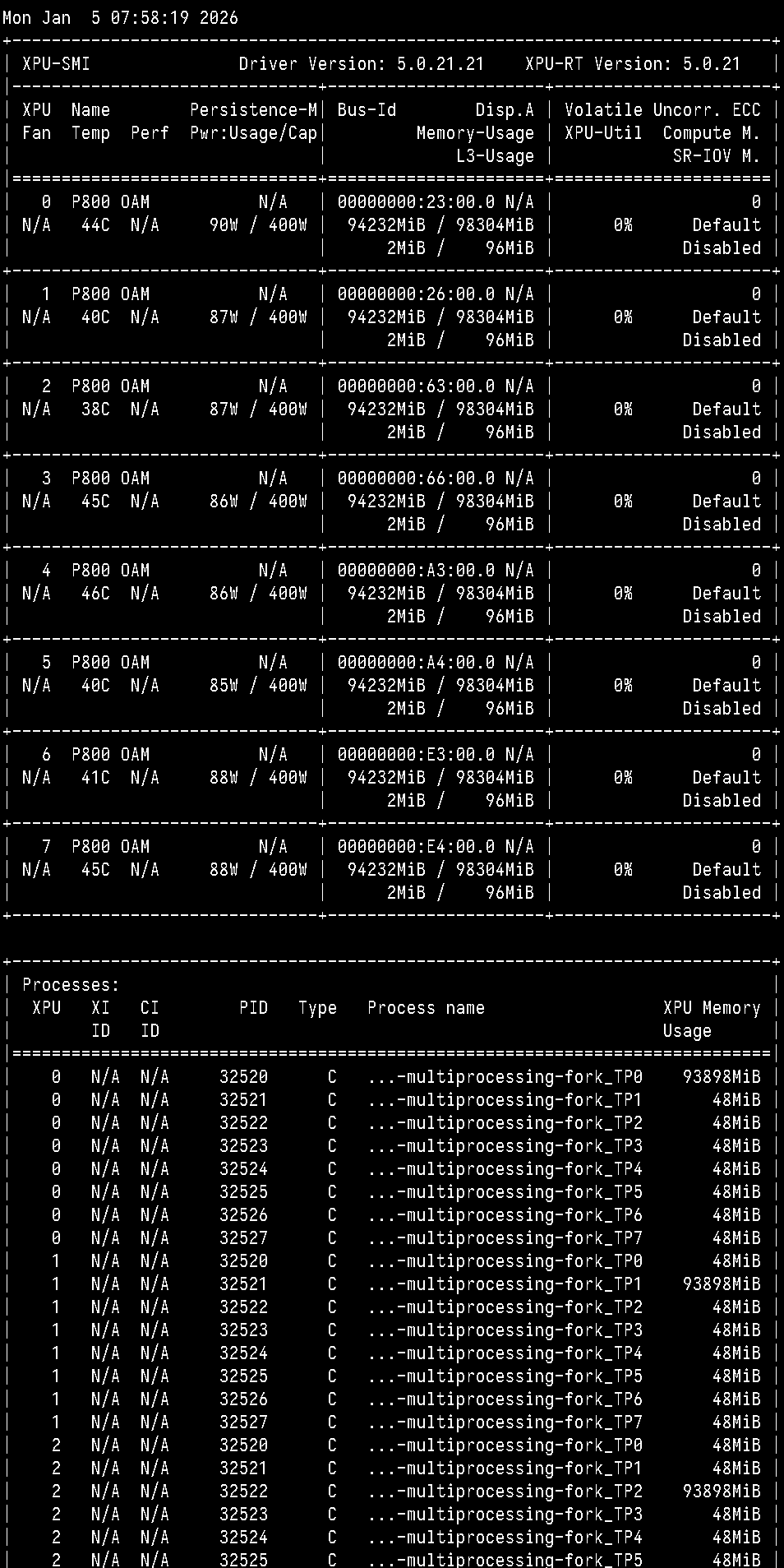
3.5 启动参数调优建议
容器中的 vLLM 启动参数与常规 vLLM 基本一致,典型需要根据业务调整的包括:
XPU_VISIBLE_DEVICES:指定使用的 P800 卡号。--model:指向 Qwen3 权重所在目录。--gpu-memory-utilization:显存利用率,一般在0.9~0.95之间调整。--max-model-len:最大上下文长度,长上下文场景需适当调大。--tensor-parallel-size:并行卡数,与XPU_VISIBLE_DEVICES保持一致。--max_num_seqs/--max_num_batched_tokens:影响吞吐和显存占用,可结合业务 QPS 目标调参。
建议:
--compilation-config与相关 XPU 环境变量通常由专家预调好,不建议修改,除非明确了解昆仑芯图编译行为。
4. 性能测试(vLLM Bench)
本节基于 vllm bench serve 对不同模型与并行配置进行压测,指标包括吞吐、TTFT(首 token 延迟)与 ITL(token 间延迟)等。
4.1 Qwen3-32B(TP=2)
压测命令示例:
vllm bench serve --host 0.0.0.0 --port 8999 --backend vllm \
--model /home/workspace/Qwen3-32B/ \
--dataset-name random --num-prompts 128 \
--random-input-len 1024 --random-output-len 1024 \
--max-concurrency 48
压测结果:
============ Serving Benchmark Result ============
Successful requests: 128
Maximum request concurrency: 48
Benchmark duration (s): 143.52
Total input tokens: 130513
Total generated tokens: 118159
Request throughput (req/s): 0.89
Output token throughput (tok/s): 823.29
Peak output token throughput (tok/s): 1152.00
Peak concurrent requests: 89.00
Total Token throughput (tok/s): 1732.65
---------------Time to First Token----------------
Mean TTFT (ms): 4233.80
Median TTFT (ms): 4543.36
P99 TTFT (ms): 7821.77
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 70.18
Median TPOT (ms): 47.09
P99 TPOT (ms): 923.11
---------------Inter-token Latency----------------
Mean ITL (ms): 45.04
Median ITL (ms): 42.86
P99 ITL (ms): 60.17
==================================================
4.2 Qwen3-32B(TP=8)
同样使用 vllm bench serve,仅更换后端配置(保持脚本一致):
vllm bench serve --host 0.0.0.0 --port 8999 --backend vllm \
--model /home/workspace/Qwen3-32B/ \
--dataset-name random --num-prompts 128 \
--random-input-len 1024 --random-output-len 1024 \
--max-concurrency 48
压测结果:
============ Serving Benchmark Result ============
Successful requests: 128
Maximum request concurrency: 48
Benchmark duration (s): 98.70
Total input tokens: 130513
Total generated tokens: 116917
Request throughput (req/s): 1.30
Output token throughput (tok/s): 1184.52
Peak output token throughput (tok/s): 1642.00
Peak concurrent requests: 86.00
Total Token throughput (tok/s): 2506.79
---------------Time to First Token----------------
Mean TTFT (ms): 1801.71
Median TTFT (ms): 1865.50
P99 TTFT (ms): 3376.12
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 42.35
Median TPOT (ms): 34.03
P99 TPOT (ms): 421.33
---------------Inter-token Latency----------------
Mean ITL (ms): 32.48
Median ITL (ms): 29.55
P99 ITL (ms): 220.38
==================================================
可以看到,从 TP=2 升级到 TP=8 后,总体吞吐与 TTFT 均有明显改善,体现了 P800 在多卡并行下的扩展能力。
4.3 Qwen3-VL-8B-Instruct(TP=4 / TP=1)
TP=4 情况下压测结果:
============ Serving Benchmark Result ============
Successful requests: 128
Maximum request concurrency: 48
Benchmark duration (s): 55.70
Total input tokens: 130513
Total generated tokens: 108218
Request throughput (req/s): 2.30
Output token throughput (tok/s): 1942.78
Peak output token throughput (tok/s): 2736.00
Peak concurrent requests: 88.00
Total Token throughput (tok/s): 4285.82
---------------Time to First Token----------------
Mean TTFT (ms): 877.81
Median TTFT (ms): 906.67
P99 TTFT (ms): 1645.36
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 40.42
Median TPOT (ms): 19.96
P99 TPOT (ms): 464.13
---------------Inter-token Latency----------------
Mean ITL (ms): 19.50
Median ITL (ms): 18.26
P99 ITL (ms): 123.94
==================================================
TP=1 情况下压测结果:
============ Serving Benchmark Result ============
Successful requests: 128
Maximum request concurrency: 48
Benchmark duration (s): 73.54
Total input tokens: 130513
Total generated tokens: 108322
Request throughput (req/s): 1.74
Output token throughput (tok/s): 1473.00
Peak output token throughput (tok/s): 2112.00
Peak concurrent requests: 88.00
Total Token throughput (tok/s): 3247.76
---------------Time to First Token----------------
Mean TTFT (ms): 1343.65
Median TTFT (ms): 1241.13
P99 TTFT (ms): 2714.13
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 41.05
Median TPOT (ms): 26.14
P99 TPOT (ms): 579.38
---------------Inter-token Latency----------------
Mean ITL (ms): 25.50
Median ITL (ms): 24.39
P99 ITL (ms): 108.66
==================================================
4.4 Qwen3-8B(TP=1)
============ Serving Benchmark Result ============
Successful requests: 128
Maximum request concurrency: 48
Benchmark duration (s): 74.09
Total input tokens: 130513
Total generated tokens: 123513
Request throughput (req/s): 1.73
Output token throughput (tok/s): 1667.00
Peak output token throughput (tok/s): 2208.00
Peak concurrent requests: 84.00
Total Token throughput (tok/s): 3428.48
---------------Time to First Token----------------
Mean TTFT (ms): 1558.48
Median TTFT (ms): 1389.65
P99 TTFT (ms): 2619.69
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 35.93
Median TPOT (ms): 24.24
P99 TPOT (ms): 39.07
---------------Inter-token Latency----------------
Mean ITL (ms): 23.48
Median ITL (ms): 23.26
P99 ITL (ms): 26.09
==================================================
这些结果为后续容量规划和参数调优提供了可靠参考。
5. Qwen3-8B 全参数 DPO 训练(LLaMA-Factory)
在完成推理部署与验证后,我们可以在同一套 P800 集群上使用 LLaMA-Factory 对 Qwen3-8B 进行全参数 DPO(Direct Preference Optimization)训练。
5.1 训练配置文件 qwen3_full_dpo.yaml
在容器内查看训练配置:
(python310_torch25_cuda) root@h3c:/workspace/LLaMA-Factory# cat /home/workspace/qwen3_full_dpo.yaml
内容如下:
### model
model_name_or_path: /home/workspace/Qwen3-8B/
trust_remote_code: true
### method
stage: dpo
do_train: true
finetuning_type: full
deepspeed: examples/deepspeed/ds_z3_config.json
### dataset
dataset: dpo_en_demo
template: qwen3_nothink
cutoff_len: 2048
max_samples: 1000
preprocessing_num_workers: 16
dataloader_num_workers: 4
### output
output_dir: /home/workspace/saves/qwen3-8b/full/dpo
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
save_only_model: false
report_to: none # choices: [none, wandb, tensorboard, swanlab, mlflow]
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 5.0e-6
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
resume_from_checkpoint: null
### eval
# eval_dataset: dpo_en_demo
# val_size: 0.1
# per_device_eval_batch_size: 1
# eval_strategy: steps
# eval_steps: 500
关键配置说明:
stage: dpo:使用 DPO 作为训练范式。finetuning_type: full:全参数微调,适合在 P800 大显存场景下追求最优效果。bf16: true:使用 BF16 训练,提高数值稳定性与性能。per_device_train_batch_size×gradient_accumulation_steps与集群卡数共同决定全局 Batch Size,可按算力与数据规模调整。
5.2 启动训练
在容器内执行:
(python310_torch25_cuda) root@h3c:/workspace/LLaMA-Factory# llamafactory-cli train /home/workspace/qwen3_full_dpo.yaml
训练开始后,会输出类似日志:
[INFO|trainer.py:2519] 2026-01-06 17:57:54,377 >> ***** Running training *****
[INFO|trainer.py:2520] 2026-01-06 17:57:54,377 >> Num examples = 300
[INFO|trainer.py:2521] 2026-01-06 17:57:54,377 >> Num Epochs = 3
[INFO|trainer.py:2522] 2026-01-06 17:57:54,377 >> Instantaneous batch size per device = 1
[INFO|trainer.py:2525] 2026-01-06 17:57:54,377 >> Total train batch size (w. parallel, distributed & accumulation) = 64
[INFO|trainer.py:2526] 2026-01-06 17:57:54,377 >> Gradient Accumulation steps = 8
[INFO|trainer.py:2527] 2026-01-06 17:57:54,377 >> Total optimization steps = 15
[INFO|trainer.py:2528] 2026-01-06 17:57:54,379 >> Number of trainable parameters = 8,190,735,360
{'loss': 0.3777, 'grad_norm': 5.166717262430514, 'learning_rate': 2.1986582993616926e-06, 'rewards/chosen': 0.015174219384789467, 'rewards/rejected': -2.6984405517578125, 'rewards/accuracies': 0.674342155456543, 'rewards/margins': 2.7136147022247314, 'logps/chosen': -442.06658935546875, 'logps/rejected': -538.8236694335938, 'logits/chosen': -0.45987415313720703, 'logits/rejected': -0.41490501165390015, 'epoch': 2.0}
...
{'train_runtime': 492.6162, 'train_samples_per_second': 1.827, 'train_steps_per_second': 0.03, 'train_loss': 0.2571491261323293, 'epoch': 3.0}
可以看到:
- Total train batch size = 64:结合卡数与累积步数计算得到的有效全局 Batch Size。
- Number of trainable parameters ≈ 81.9 亿:对应 Qwen3-8B 全参数。
- train_loss 逐步下降,说明训练稳定收敛。
显存与算力占用示例(DPO 训练阶段):
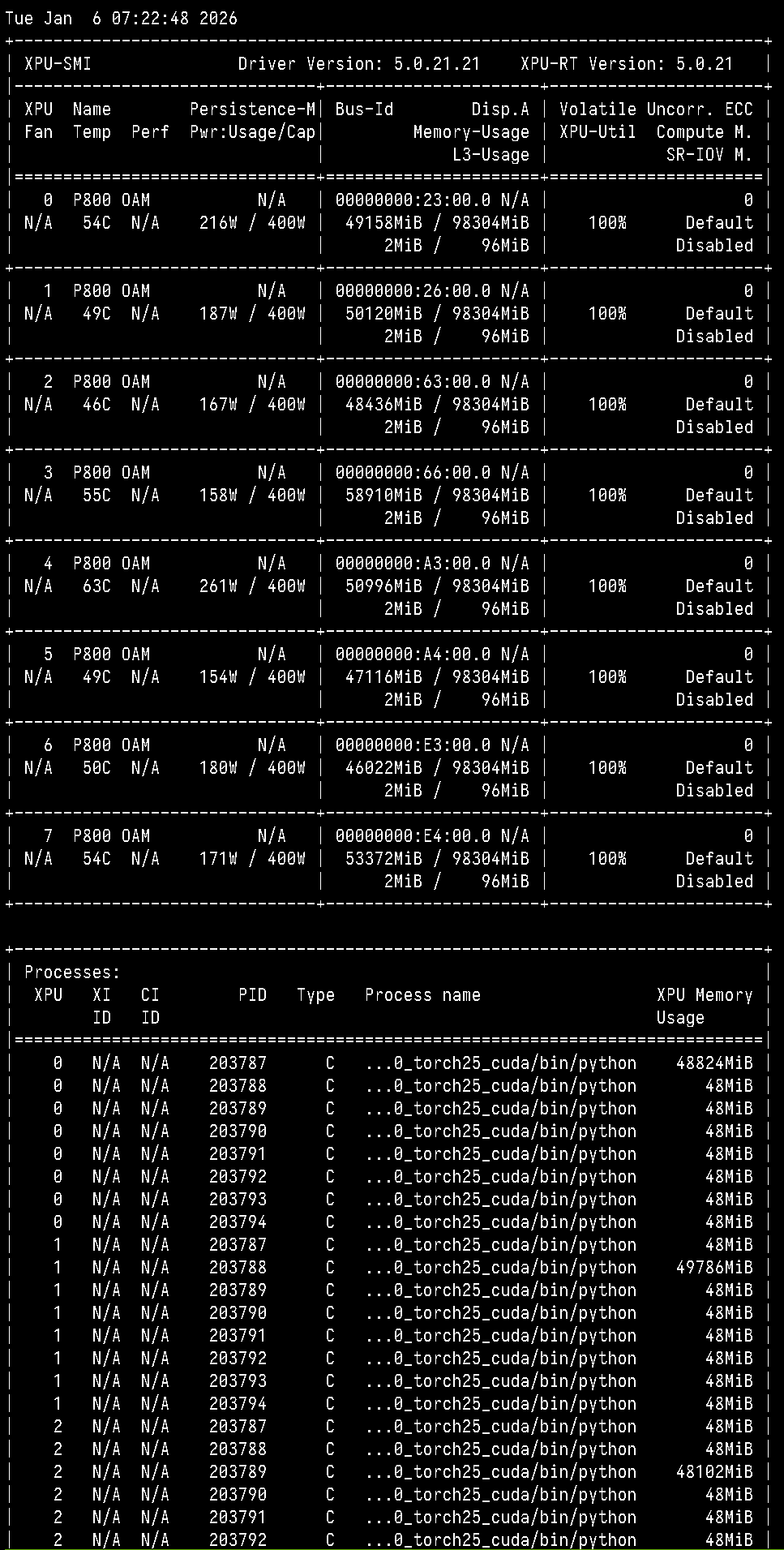
5.3 Checkpoint 与导出结果
训练过程中会按照 save_steps 定期保存中间 Checkpoint,结束时会再保存最终权重,日志示例如下:
[INFO|trainer.py:4309] 2026-01-06 18:04:45,789 >> Saving model checkpoint to /home/workspace/saves/qwen3-8b/full/dpo/checkpoint-15
...
[2026-01-06 18:06:05,793] [INFO] [engine.py:3478:_save_zero_checkpoint] zero checkpoint saved /home/workspace/saves/qwen3-8b/full/dpo/checkpoint-15/global_step15/bf16_zero_pp_rank_0_mp_rank_00_optim_states.pt
...
[INFO|trainer.py:4309] 2026-01-06 18:06:19,884 >> Saving model checkpoint to /home/workspace/saves/qwen3-8b/full/dpo
训练完成后,输出目录结构如下:
(python310_torch25_cuda) root@h3c:/workspace/LLaMA-Factory# ls /home/workspace/saves/qwen3-8b/full/dpo
added_tokens.json checkpoint-15 merges.txt model-00003-of-00004.safetensors README.md tokenizer.json training_args.bin train_results.json
all_results.json config.json model-00001-of-00004.safetensors model-00004-of-00004.safetensors special_tokens_map.json trainer_log.jsonl training_loss.png vocab.json
chat_template.jinja generation_config.json model-00002-of-00004.safetensors model.safetensors.index.json tokenizer_config.json trainer_state.json training_rewards_accuracies.png
model-0000x-of-00004.safetensors:分片后的权重文件,可直接用于推理。training_loss.png/training_rewards_accuracies.png:训练过程可视化图。chat_template.jinja:聊天模板,便于在 vLLM 或自研服务中复用。
下一步:可以将该目录挂载到新的 vLLM 容器中,将
--model指向该路径,以验证 DPO 训练效果。
6. 常见问题与排查建议
结合实测经验,总结几个在昆仑芯 P800 上部署 Qwen3 时常见的问题与排查思路。
6.1 vLLM 服务启动慢
- 现象:首次启动耗时较长,日志中显示 Graph capturing / warmup。
- 原因:vLLM-Kunlun 需要对计算图进行编译与缓存,属于正常现象。
- 建议:首次启动耐心等待 5–15 分钟,后续重启会显著加快。
6.2 显存不足(Out of Memory)
- 降低
--max-model-len、--max_num_seqs、--max_num_batched_tokens。 - 适当减小
--gpu-memory-utilization,避免过度吃满显存。 - 确认没有其他进程占用同一块 P800 显存。
6.3 性能未达预期
- 优先确认是否正确设置了
XPU_VISIBLE_DEVICES与--tensor-parallel-size。 - 使用
xpu-smi检查算力利用率与温度,排除硬件限频问题。 - 对比 TP=1 / TP>1 的 Bench 结果,验证多卡扩展是否正常。
7. 总结与扩展方向
本文基于真实生产环境,完整演示了 昆仑芯 P800 XPU 上 Qwen3 系列模型的推理与全参数 DPO 训练实践:
- 从 物理机环境检查、容器镜像选择 到 vLLM-Kunlun 推理服务部署,给出了可直接复用的脚本与参数说明。
- 基于 vllm bench serve 的压测结果,为后续容量规划与性能调优提供了参考。
- 借助 LLaMA-Factory,实现了 Qwen3-8B 的全参数 DPO 训练,并解析了训练输出结构。
在此基础上,你可以进一步尝试:
- 将本指南迁移到多机多卡 P800 集群上,验证跨节点的张量并行能力。
- 使用自有偏好数据替换示例数据集,完成面向具体业务场景的对齐训练。
- 结合企业内部服务框架,将 vLLM OpenAI 接口封装为统一的模型服务网关。